特色功能
Y-Trainer 特色功能介绍
🚀 Y-Trainer 特色功能
🧠 核心算法:基于梯度的非线性学习强度调节算法
Gradient-driven Nonlinear Learning Intensity Regulation (NLIRG)
NLIRG 是我们的核心创新算法,通过实时监测训练样本的难易度,并根据样本难度动态调整训练强度,实现模型训练的精准调优,同时有效缓解过拟合问题。
工作原理:
- 实时监测每个训练样本的难易程度
- 根据样本难度动态调整学习强度
- 优化训练过程,提高模型泛化能力
使用方法:
只需在训练启动脚本中添加 --use_NLIRG 'true' 参数即可启用此功能。
# 启用NLIRG算法的训练命令示例
python -m training_code.start_training --use_NLIRG 'true' [其他参数...]🛠️ 工具兼容性
多卡训练支持
内置 DeepSpeed Stage3 支持,轻松实现多卡分布式训练,解决单卡显存不足的问题。
优势:
- 自动处理多卡通信和同步
- 显存优化,支持更大模型训练
- 简化配置,无需复杂设置
LoRA 训练支持
通过 use_lora 参数即可启用 LoRA 训练,特别适合资源有限的场景。
优势:
- 大幅降低需要训练的参数量
- 显著减少显存需求
- 生成极小的权重文件,降低存储压力
- 支持快速多任务微调
# LoRA训练示例
python -m training_code.start_training --use_lora 'true' [其他参数...]🤖 模型兼容性
以下是我们已测试验证的模型兼容性列表:
| 模型系列 | 兼容性 | 备注 |
|---|---|---|
| Qwen-2.5 | ✅ | 1.5B~14B |
| Qwen-3 | ✅ | 1.5B~14B |
💡 提示:除上述模型外,其他基于 Transformer 架构的模型通常也兼容,但需要用户自行验证。
📊 TensorBoard 可视化支持
内置 TensorBoard 可视化功能,提供直观的训练过程监控。
功能特点:
- 实时监控训练损失和指标
- 可视化模型训练进度
- 支持多种图表类型
使用方法:
启动Tensorboard
tensorboard --logdir=/path/to/logs
# 启动后,按照命令行提示在浏览器中访问即可实时查看训练情况设置训练时TensorBoard记录
# 指定TensorBoard日志路径
python -m training_code.start_training --use_tensorboard 'true' --tensorboard_path /path/to/logs
# 或使用默认路径(输出目录下)
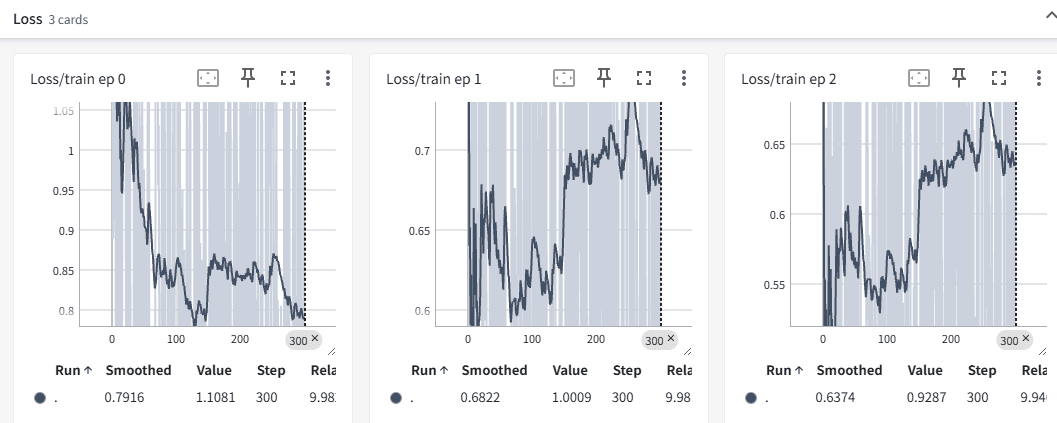
python -m training_code.start_training --use_tensorboard 'true' --output_dir /path/to/output无论是否指定 TensorBoard 日志路径,系统都会在 --output_dir 指定的路径下自动生成训练损失图表。
例子如图:
📈 实用工具:指令微调语料排序
智能语料难易度评估
此工具基于模型面对语料时熵与交叉熵的整体时序差异来评估语料的难易度,帮助开发者获得难度递增的微调语料。
应用场景:
- 构建渐进式训练数据集
- 优化模型学习路径
- 提高训练效率和效果
使用示例
# 调用排序脚本,对指令微调数据按照与模型的相似度排序
# 参数说明:
# --data_path: 原始指令微调数据 JSON 文件路径
# --output_path: 排序后输出的 JSON 文件路径
# --model_path: 用于推理和排序的基础模型(如 Qwen3-8B)
# --mode: 排序策略,此处为 "similarity_rank"(曲线相似度排序)
cd ~/y-trainer
python -m training_code.utils.schedule.sort \
--data_path example_dataset/sft_example.json \
--output_path example_dataset/sft_example_out.json \
--model_path Qwen3/Qwen3-8B \
--mode "similarity_rank"排序策略说明
- similarity_rank:基于曲线相似度的排序策略
- 其他排序策略可根据需求扩展
🔗 相关文档
💡 了解更多:Y-Trainer 致力于提供高效、易用的大模型训练解决方案,持续优化用户体验和训练效果。
How is this guide?
最后更新